How news media frame data risks in their coverage of big data and AI
Abstract
Public discourses have become sensitive to the ethical challenges of big data and artificial intelligence, as scandals about privacy invasion, algorithmic discrimination, and manipulation in digital platforms repeatedly make news headlines. However, it remains largely unexplored how exactly these complex issues are presented to lay audiences and to what extent news reporting—as a window to tech debates—can instil critical data literacy. The present study addresses this research gap and introduces the concept of “data risks”. The main goal is to critically investigate how societal and individual harms of data-driven technology find their way into the public sphere and are discussed there. The empirical part applies a mixed methods design that combines qualitative and automated content analyses for charting data risks in news reporting sampled from prominent English-speaking media outlets of global reach. The resulting inventory of data risks includes privacy invasion/surveillance, data bias/algorithmic discrimination, cybersecurity, and information disorder. The study posits data risks as communication challenges, highlights shortcomings in public discussions about the issue, and provides stimuli for (practical) interventions that aim at elucidating how datafication and automation can have harmful effects on citizens.Introduction
Critical data studies (CDS) focus on ethical challenges and societal risks of datafication and automation. Key subjects are undemocratic power hierarchies governing digital transformation (Taylor, 2017; van Dijck et al., 2021; Dencik & Sanchez-Monedero, 2022), exploitation and subjugation (Zuboff, 2019; Couldry & Mejias, 2019), biases and exclusion (Benjamin, 2019; D’Ignazio & Klein, 2020; Lopez, 2021), privacy, surveillance, and cybersecurity (Solove, 2021; Landau, 2017), and harmful effects of algorithmic content distribution (e.g., Ireton & Posetti, 2018). These risk dimensions are complex, contextual, and overlap. For example, systems for algorithmic policing can invade individuals’ privacy and subject them to discriminatory governing practices that are racist (Browning & Arrigo, 2021). Numerous studies highlight negative effects of prevailing data practices and criticise inequality, unfairness, and the unethical treatment of different social groups (Dencik & Sanchez-Monedero, 2022). Given their links to data-driven technologies, these risks are subsumable as data risks.
While the academic discourse underlines the urgency of addressing data risks, Western public discourses have also become sensitive to the ethical implications of big data and artificial intelligence (AI). Scandals about privacy invasion, algorithmic discrimination, and manipulation in social media repeatedly make news headlines (Hinds et al., 2020; Simon et al., 2020), which is a “seismograph” for public debates. However, it seems that data risks have not (yet) become prominent topics in political campaigning or social activism beyond niche movements. Furthermore, empirical research only recently started to investigate laypeople’s views on these issues (Hartman et al., 2020). Experiences, attitudes, opinions, and actions are moulded by and contribute to socio-technical imageries that emerge in technology-centric discourses (Bareis & Katzenbach, 2022). From this angle, critically analysing tech discourses reveals power hierarchies and the dynamics behind prevalent narratives that determine what constitutes a benefit or risk (as in harm or threat) connected to technology.
While there is rich literature on each data risk category (Mejias & Couldry, 2019; D’Ignazio & Klein, 2020; Wolff, 2022; Benjamin, 2019), there is so far no comparative view on how they are contextualised and presented to broader lay audiences that constitute media publics. Important questions concern the framing of data risks, commonalities and differences between risk portrayals, perceived urgencies (and possible rankings), and the real or imagined effects for individuals and communities.
There are two reasons for zoning-in on news media. First, news media are integral to constructing shared spheres of communication beyond singular communities in society (Peters, 2007). News reporting can contribute to audiences’ perceptions and evaluations of digital technologies in different ways, e.g., via simple product reviews, critical reporting about data scandals, or the contextualisation of tech against the background of geopolitical developments (Nguyen & Hekman, 2022a). From a normative perspective, if critical journalism has potential for raising awareness about unfairness, inequality, and injustice in society, then similar societal challenges where datafication and automation are key factors should not be an exception. However, even if one does not assign a normative function to journalism, the way news media report about and make sense of data-driven technologies may still contribute to the formation of socio-technical imageries around emerging technologies, i.e., how their affordances, effects, benefits, harms, and risks are perceived in society (Vincente & Dias-Trindade, 2021).
Second, on an individual level, consumption of news about datafication and AI can potentially factor into the accumulation of fact-based knowledge about these issues and to the development of critical perspectives. Tech news reporting can be considered as a component in building ‘critical data literacy’ (Nguyen & Nguyen, 2022): a combination of critical-conceptual and practical knowledge and skills about how data-driven systems affect personal privacy, digital security, empowerment, and societal fairness. This concerns media audiences as citizens and professionals alike; what they learn about tech in the news may shape their personal and professional views. However, critical data literacy also concerns journalistic organisations themselves. Tech news is prone to “hype” and the complexity of big data and AI developments demand expert knowledge to explain them accurately yet accessibly to lay audiences.
Before the potential contribution of news reporting to critical data literacy among media publics can be assessed, it is imperative to critically analyse current practices in data risk news coverage. The goal of the study is to describe data risk framing and then to gauge how tech journalism could improve to make it more valuable for building critical data literacy among lay audiences. This may include building such a literacy within the journalistic profession first. Additionally, the analysis can help policymakers and organisations with assessing their own communication strategies about data risks.
The present study’s theoretical framework draws from CDS, media studies, public sphere theory, sociology of risks, and news framing research. The empirical part combines computational methods for automated content analysis (distant reading) with a critical summary of representative examples for news articles that discuss data risks (close-reading). Focus is placed on big data and AI for their visibility in contemporary public discourses and the prevalence of associated narratives about their perceived transformative potentials. They are not representative of all tech developments where data risks matter but are suitable examples for exploring how tech trends are connected to possible downsides.
The computational part utilises topic modelling (TM) for identifying dominant themes in tech news coverage in combination with a so-called dictionary approach that identifies risk references in news content. The sample includes mainstream- and tech news outlets from the US and UK that covered the topics “artificial intelligence” and “big data” between 2010 and 2021. Taking a historical view allows for exploring how data- and AI discourses changed over time and to spot moments in which specific data risks drew media attention. The sample consists of 5,423 articles for the distant reading; 400 articles were selected for the close-reading. The findings allow 1) to uncover general patterns in news reporting about data risks, and 2) to explore how data risks are defined, construed, and portrayed in the news.
The paper is structured as follows: First, the role of tech news reporting in public discourses is discussed and linked to the concept of critical data literacy. The main argument is that tech news can stimulate the emergence of more critical media publics by contributing to their awareness and understanding of datafication and automation. Second, data risks are defined as interrelated discursive constructions that emerge within but also shape socio-technical imageries. Data risks are man-made in two fundamental ways: 1) through the intended or unintended unethical use of technology and 2) the choice of words, metaphors, contexts, and associations through which they are conceptualised and discussed in public discourses. This links data risks to news framing theory. Third, the empirical investigation combines computational-quantitative with qualitative methods via a content analysis of tech news. The results show how data risks are clearly present in Anglophone-Western tech news discourses but that the value for building critical data literacy among lay audiences varies greatly between reporting styles. The paper closes with a critical reflection on the role of tech media discourses for tech adoption and regulation.
News reporting and technology discourses
From a Western perspective, news media in liberal-democratic political systems ideally serve as critical observers of those in power and provide a common public forum for the discursive processing of issues of societal relevance (Peters, 2007). While this idealised vision may appear out of touch with a reality where dynamic media landscapes are shaped by economic pressures (Peterson, 2021), elite orientation (van Duyn & Collier, 2018), and the digital reconfiguration of public discursivity (Bro & Wallberg, 2014), news media are still essential for establishing shared societal contexts (Goenaga, 2022; Langer & Gruber, 2020). They may not be capable of capturing a society’s full spectrum of viewpoints but remain influential in determining what issues, events, developments, and assessments gain visibility across singular societal domains and social strata.
Technological trends are staples in news agendas. Past examples are nuclear energy, nanotechnology, and biotechnology (Cacciatore et al., 2012; Scheufele & Lewenstein, 2005; Marks et. al., 2007). Technologies’ newsworthiness derives from their social and economic implications, which are frequently at the centre of social, cultural, and political deliberations (e.g., what are acceptable uses of a new technology? Should new technologies be regulated and if so, how?). News reporting focuses on different expected impacts of technologies, with particular interest in beneficial and harmful outcomes. The allocation of societal relevance differs vastly between technologies and the perception of impact changes over time. Longitudinal developments are often marked by bouts of heightened public attention that connect to innovations, breakthroughs, incidents, and regulatory intervention followed by “droughts” of media attention. For example, nanotechnology was at the centre of increased media coverage between 2000 and 2008 (Donk et al., 2011) but currently has limited news value.
Technology news coverage today largely overlaps with reporting about different aspects of digital transformation. This takes place in two concrete ways of tech news reporting. On the one hand, all news sections (e.g., politics, economy, culture, sports) need to consider the introduction and effects of digitalisation, datafication, and automation. On the other, tech news evolved into an additional, distinct news section with a diverse spectrum of topics. These include advances in fundamental research, product reviews, tech business developments, data scandals, tech regulation, and other stories centred on data-driven tech (Nguyen & Hekman, 2022b). Tech news places its focal point on how data and automation enter different spheres of public and private life -or have the potential to do so in the future. The visibility of tech issues across news sections and the emergence of tech news as a separate journalistic domain are evidence for the general news value of and public interest in digital transformation as a societal phenomenon. As a result, the rise of big data and AI is archived in news content on different aspects of their transformative potentials, values, and risks through the lens of journalism. News media as observers of tech developments provide a general view on contemporary tech discourses.
They fulfil this societal function through a dual role in public discourses: news media are stages for as well as commentators on current issues. Various entrepreneurial, political, and cultural perspectives find a common stage in tech news that shares trends, visions, and assessments with media audiences. In this way, tech news reporting diffuses prevalent ideas, narratives, propositions, attitudes, themes, and tensions that “make” contemporary tech discourses. This includes how data-driven technologies are filled with meaning, connected to expectations, and become incrementally “normalised” across societal domains.
However, news media are not impartial mirrors for technology discourses in which non-media stakeholders simply get to share their views but offer their own assessments of issues and stakeholders (Nguyen, 2017). Each news organisation has its ideological background, cultural setting, business model, and leading values that shape journalistic practice (Hepp et al., 2012). As active discourse participants, news media co-shape technology discourses along with actors from business, research, and politics. This happens on the level of the public sphere through news framing practices, agenda-setting, and priming. It matters for public perception and imagination what aspects of emerging technologies are in focus of news reporting, how they are presented, and who gets to speak about them. News media contribute to the allocation of societal relevance and the politicisation of tech issues, which has the potential to stimulate discussions about tech governance. Or, vice versa, tech news reporting can make media publics aware of tech developments that pose ethical issues in need of regulation and how lawmakers intend to address them.
Tech trends can be difficult to translate for public audiences, depending on the level of perceived complexity or, put differently, how easily they can be explained in accessible language that facilitates the formation of mental models (Roskos-Ewoldson et al., 2004). Some technologies are “concrete” (e.g., cloning, fracking), while others are elusive and versatile. Examples of the latter are big data and AI. In short, big data describes diverse forms of data collection and analysis on an enormous scale and high level of granularity. AI is an umbrella term for algorithms that utilise large amounts of data for automating processes. Aside from their technical meaning, both terms have epistemological and ideological connotations connected to a new data empiricism and technological determinism that transforms practices in diverse sectors (Kitchen, 2021). Given the costs involved for developing, deploying, and benefitting from big data and AI, they raise questions about fairness, access, and democracy (Srincek, 2017).
Tech news and Critical Data Literacy
Big data and AI are virtually omnipresent but appear abstract to non-experts, which can lead to misconceptions of how data and algorithms work (Zarouali et al. 2021). An important factor likely to shape perceptions of relevance and impact is the felt remoteness vs. immediacy of effects of technology. With big data and AI, this is an ambivalent situation. They appear abstract, complex, and difficult to grasp, yet digital systems utilising data and automation are ubiquitous. Everybody is exposed to a “data gaze” when interacting with digital interfaces. These hide the inner workings of algorithms behind carefully curated and framed “user experiences” of products and services. Critical voices point to a lack of transparency and companies as well as governmental organisations have been accused of applying strategic “black-boxing” to obscure their data practices (Pasquale, 2015). The role of digital technology in daily life is a matter of public concern as it touches on several important societal dimensions such as individual well-being, labour markets, economic growth, social stratification, culture, politics, safety, and security.
Only a few studies critically analyse news reporting about big data and AI (Bunz & Braghieri, 2021; Paganoni, 2019; von Pape et al., 2017). Their main research interest is to explore how news coverage may shape citizens’ understanding of datafication and automation. This links to critical data literacy and how tech news coverage may contribute to building it. Critical data literacy is defined here as conceptual knowledge about datafication and automation among laypeople and their capabilities to form critical opinions (Nguyen, 2020). From this angle, critical data literacy mostly concerns a critical understanding of 1) how data practices and algorithmic systems affect individuals directly in respect to e.g., personal privacy, data security, and fairness (esp. in the context of automated decision-making); 2) how organisations accumulate power and wealth through data and AI and what that means for a fair and open society; 3) how individual citizens can protect themselves better from harmful data practices; and 4) how the implications of big data and AI should be subject of (democratic) governance. The proposed take on critical data literacy links the individual-practical to the societal-political dimensions and builds on previous propositions that mainly focus on each separately (Pangrazio & Selwyn; Gray et al, 2018).
By reporting about privacy issues, data abuses, data biases etc., news media can provide their audiences with important information for critically thinking about datafication and automation. However, news media are only one factor in building critical data literacy next to education and personal experiences. Yet concerning awareness and conceptual understanding of big data and AI and their diverse effects, news media fulfil a crucial function for public information. In fact, mainstream news media such as the New York Times made explicit how their tech reporting aims at helping their audiences to think more critically about the societal impact of tech and how to protect themselves better (Chen, 2022).
Data risks and news framing
Risk as a sociological concept is not always clearly defined and sufficiently discussed in critical data studies literature. Most studies focus on specific ethical challenges of certain uses of data-driven technology. Analysing how risks become topics in public discourses and how they are framed adds an important layer to the critical understanding of digital technology’s role in society. News media play an essential role in the construction of social reality, including risks as issues of societal relevance with tangible effects on different parts of society (Lupton, 2013). News media outlets tend to assign news values (Harcup & O’Neill, 2016) to novel and impactful technologies especially if their societal effects are controversial. Negative outcomes, whether actual or imagined, located in the present or a (vague) future, are naturally part of media narratives about technologies. Challenges and risks are discursive constructs that largely depend on context and perspective. The socio-cultural situatedness of individuals and social groups steer the perception of what trends, developments, and practices are considered “problematic” and which ones are not (Luhmann, 1991; Wynne, 2002; Beck, 2008). The definition of risk in the present study places emphasis on potentially negative and harmful impacts -intended, unintended, acknowledged, or downplayed- of big data and AI. Risks are not fixed but “fluid”, as they emerge, change, and disappear over time. Changing cultural norms, consumption trends, political trends, and new scientific insights are some of the factors that shape risks and the evaluation of their societal gravity.
News media can make lay audiences aware of diverse manifestations that benefits and risks of technology have for different social groups (Paek & Hove, 2017). News framing of issues contributes to the portrayal of “riskiness” and dimensions of effect. This can shape technology perception and attitude formation through framing practices, i.e., what parts of complex realities news reporting highlights with different evaluative emphases. News framing directly and indirectly contributes to public understanding of technological transformations. This is not to say that news media must fulfil a normative function as somehow unbiased, impartial, and objective-critical observers (which, taken as a whole, they cannot). The exact ways in which news covers and portrays technology depends on diverse factors, such as current trends (and fads) and the cultural context in which news media are located.
For example, Laor et al. (2021) show how the popularity of the Pokemon GO mobile game triggered a media panic in the Israeli news discourse centred on the perceived negative effects of augmented reality on users’ health and safety. News overhyped the downsides of tech in this case. For the German context, von Pape et al. (2017) show how the issue of privacy became a nuanced topic for news reporting that critically covers data practices of organisations. Over time, different views, assessments, and a heightened sense for the importance of the issue emerged. While scandals and data leaks shape news coverage of privacy, the authors show that ‘changes come from events that have the potential to enhance privacy in the future’ (von Pape et al., 2017: 1). However, risk perceptions in media discourses are not necessarily congruent with risk perceptions within communities and/or on an individual level. Concerning privacy issues, Solove (2021) argues that users are not ignorant but rather quite conscious about the risks of data sharing and perform virtually constant risk-benefit calculations with each digital engagement.
News framing can have an “awareness effect” on audiences by simply informing them about what aspects of an issue are on the public agenda, especially with respect to benefits and risks. One example is the Cambridge Analytical scandal involving Facebook in 2017. Broad media attention pushed the issue of privacy invasion and manipulation on the public agenda. So much so that Facebook/Meta CEO Mark Zuckerberg was invited to the U.S. Congress to explain his company’s data practices (to mostly data- and digital media illiterate politicians). News media gave the case public visibility that indicated societal relevance. They critically commented on the company’s actions and reactions of regulators following the revelation of the scandal. They made ethical issues around “Big Tech” subject of public discourse.
Several points must be critically noted here. First, there is a strained relationship between news media organisations and large online platforms, who fundamentally disrupted the media landscape over the past two decades. News media organisations would overall benefit from stronger regulation of tech companies. Second, news media did not necessarily portray the problem and its scope accurately and sensationalism is not uncommon in tech scandal reporting. Third, news media do not have a monopoly over public discursivity. Social media reach billions of users and offer plenty of potential for creating alternative public spheres, even though these might be ruled and exploited by the companies behind them. The relationship between news media and social media should be understood as mutually influential. That is not to say that they are equally powerful or equally relevant for all audiences. Yet it cannot be reasonably claimed that news media are irrelevant in the digital public sphere either. Fourth, cultural context matters for how news organisations operate and eventually frame issues, including big data and AI. While not bound by any national borders, the exact manifestations of datafication and automation, their speeds, and vertical reach across social strata are to a considerable extent configured by regional and local frameworks for technology development and adoption. These frameworks consist of cultural, political, economic, and regulatory factors, with one affecting the other. In the “global West”, public discourses on digital transformation appear to be marked by contradicting tendencies between celebrating and criticising the rise of data-driven technologies (Nguyen & Hekman, 2022b).
Based on the above discussion, the present study proposes the following exploratory research question: how do news media frame data risks in their coverage of big data and AI? By analysing prevalent framing practices, news reporting will be critically assessed for its possible relevance in building-up critical data literacy among media audiences.
Method and data
To explore tech news in respect to ‘emphasis frames’ (Chong & Druckman, 2007), topic modelling using latent dirichlet distribution (LDA) was applied to the sampled text corpus with the GENSIM package for Python (Řehůřek & Sojka, 2010). Emphasis frames denote topical foci in news reporting, i.e., different contexts in which tech trends are discussed (Burscher et al., 2016). Afterwards, samples of articles referring to data risks were pulled for a qualitative content analysis.
The news articles were retrieved from five English-speaking mainstream and technology-focused news outlets: The New York Times (NYT), The Guardian, Wired, and Gizmodo. These have wide public reach among Anglophone audiences and focus on big data and AI. The NYT and the Guardian are considered mainstream newspapers that cover a broad range of topics but also frequently report about tech developments. Wired and Gizmodo are tech-centric outlets that have a smaller range of topics and cover tech regarding social, political, and cultural implications. While this sample has limitations for researching global tech discourses, it still allows for probing how influential mainstream- and tech news media make sense of emerging technological trends. The analysis focuses on the decade between 2010 and 2021, during which big data and AI underwent a succession of innovation boosts, found wider societal applications, and were frequently covered in news reporting.
Relevant articles were identified via keyword searches for ‘big data’ and ‘artificial intelligence’ / ‘A.I.’. This yielded a total of 17,813 articles. However, many articles mention either big data or AI only passingly. To increase the probability that articles explicitly discuss big data and/or AI, an additional selection criterion was set (Burscher et al., 2016): the search terms needed to occur at least once in an article’s title/headline or at least three times in the main text. This reduced the data volume to 5,423 articles (table 1). Manual validation of a random sample of 250 articles confirmed that ca. 85% of articles indeed primarily covered big data and/or AI.
|
Outlet |
AI |
Big data |
|---|---|---|
|
TheNew York Times |
2,229 |
866 |
|
Guardian |
111 |
160 |
|
Wired |
1375 |
475 |
|
Gizmodo |
102 |
105 |
The news texts were pre-processed with standard NLP-methods (i.e., lemmatising, lowercasing, feature selection, stop-words removal) prior to topic modelling. A key challenge in topic modelling is to decide on the number of topics, which needs to be set manually and can appear highly subjective. One statistical approach to narrow down the “optimal” number of topics is calculating so-called coherence scores for different topic numbers. High coherence scores are associated with higher human interpretability of generated topics (Atteveldt et al., 2022). However, they are merely a heuristic and human validation is necessary for confirming whether clusters of co-occurring words indeed form distinguishable topics. Coherence scores for 2 to 20 topics were calculated. For the pre-processed text corpus, 12 topics had the highest coherence score (0.47). Manually checking the top ten keywords per topic and inspecting examples confirmed that the 12 topics were coherent and interpretable. Two researchers labelled the topics independently and then discussed their results before settling for final labels that describe each topic accurately. Finally, a dictionary with relevant keywords as indicators for specific data risks was compiled, based on relevant literature and observations from the close-reading (table 2; Nguyen & Hekman, 2022b). Whenever an article mentioned an indicator, the respective data risk was counted as present in an article.
To test human-computer agreement, a random sample (N=250) was selected for manual coding to verify the presence of the indicated data risks. Two human coders were involved in the process with intercoder reliability between them and the automated content analysis reaching KALPHA=0.80 (Hayes & Krippendorff, 2007). However, a clear limitation is that the dictionary only includes indicators that were spotted during the qualitative analysis. In a few cases (ca. 15%), the indicators assigned to data risks were not directly related to big data and/or AI, due to a lack of context awareness of the dictionary approach.
While the computational methods provide a quick overview of general trends, they are not useful for researching framing regarding the nuanced use of words and thus are insufficient for a more comprehensive critical analysis if deployed alone. Close-reading of news texts with manual methods was thus indispensable for gaining a more fine-grained and complex analytical impression of tech news reporting.
|
Data risk |
Indicators (examples) |
|---|---|
|
Privacy invasion/surveillance |
Privacy invasion, surveillance |
|
Data bias/algorithmic discrimination |
Racism, sexism, discrimination |
|
Cybersecurity |
Cybercrime, data theft |
|
Information disorder |
Fake news, misinformation |
To explore how exactly data risks are discussed within a specific context, 400 articles were randomly sampled (100 per major data risk category) for the close-reading. The qualitative content analysis centred on themes, framing practices, metaphors as well as the depth of discussions around a given data risk.
Findings
Distant-reading of tech news
Articles focusing on big data and AI grew in numbers over the years, with a noticeable increase in the mid-2010s (figure 1). The rise and drop of media attention per tech keyword seem to coincide with “hype-cycles”: in the years 2010 to 2013, big data attained considerable attention in research and business discourses. In the years after, focus shifted to AI. Breakthroughs in machine learning, neural networks, and the introduction of AI applications in different domains are likely reasons for that. However, after peaking in 2021, the number of articles on AI (and big data) dropped considerably.

The results of the topic modelling imply that big data and AI are discussed in a variety of contexts that generally pertain to research and development, platforms and products, and impacts across societal domains. The twelve different topics that emerged from the analysis (table 3) are further clustered into four larger themes (table 4).
|
Topic |
N |
% of Total |
|---|---|---|
|
International Politics & Finance |
590 |
10,9 |
|
AI, Robots, and Tech |
606 |
11,2 |
|
Platforms & Tech Infrastructure |
653 |
12,0 |
|
Tech Products |
232 |
4,3 |
|
AI & Machine Learning |
345 |
6,4 |
|
International Politics & Security |
524 |
9,7 |
|
AI & Tech Research |
422 |
7,8 |
|
US Politics |
616 |
11,4 |
|
AI, Platforms & Healthcare |
600 |
11,1 |
|
AI Tech & Privacy |
466 |
8,6 |
|
Tech Platforms and International Politics |
240 |
4,4 |
|
Arts & Culture |
129 |
2,4 |
|
TOTAL |
5423 |
100 |
|
Theme |
N |
% Total |
|---|---|---|
|
AI, big data & politics (topics 1, 6, 8, 11) |
1,970 |
36,3 |
|
AI & big data research (topics 2, 5, 7) |
1,373 |
25,3 |
|
Big tech platforms & products (topics 3, 4) |
885 |
16,3 |
|
The automated-datafied society (topics 9, 10, 12) TOTAL |
1,195
5,423 |
22,0
100 |
The framing of big data and AI seems to have undergone diversification from a science topic into a matter of wider societal relevance and increasing politicisation (figure 2). The portrayal of big data and AI as political issues gained increasing visibility as of 2016 and concerns national as well as international politics. Since most of the sampled news outlets are US-based, this often links to US politics on the national level but also frequently involves China on the global stage.

During the manual content analysis, four dominant data risk categories emerged that were then quantified with the help of computational analysis: cybercrime/cyberwar, information disorder (mis- and disinformation), surveillance, and data bias. Each category is defined and explored in more detail below but before that, figures 3 to 5 provide a general overview for the distant-reading. The numbers for explicit data risk references in news articles increased over time. Taken together, 47% of AI-centric articles and 46% of big data-focused articles include a data risk reference. This implies that tech news has become more attentive to these issues. However, as of 2020 explicit data risk references started to drop. It is noteworthy that only privacy and security (linking to cyberwar/cybercrime) emerged as dominant (partial-)topics in the topic modelling (table 3), while all other data risks appear as sub-dimensions of other news frames.
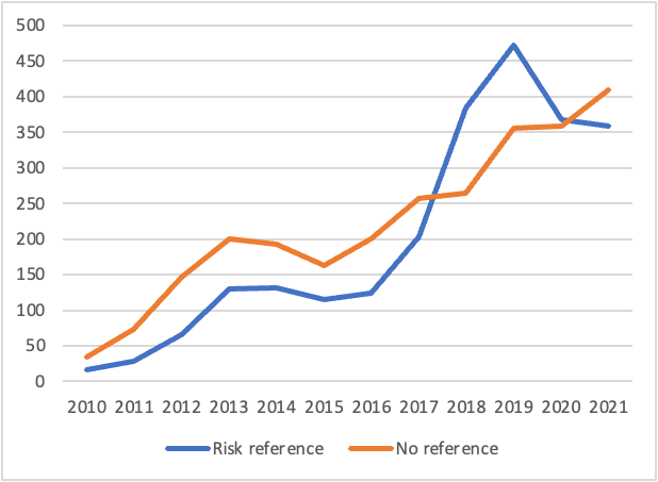
The four major data risk types are present in articles for both keywords big data and AI. Figures 4 and 5 show how the four categories were distributed in news articles that included any risk reference(s) for a given year.
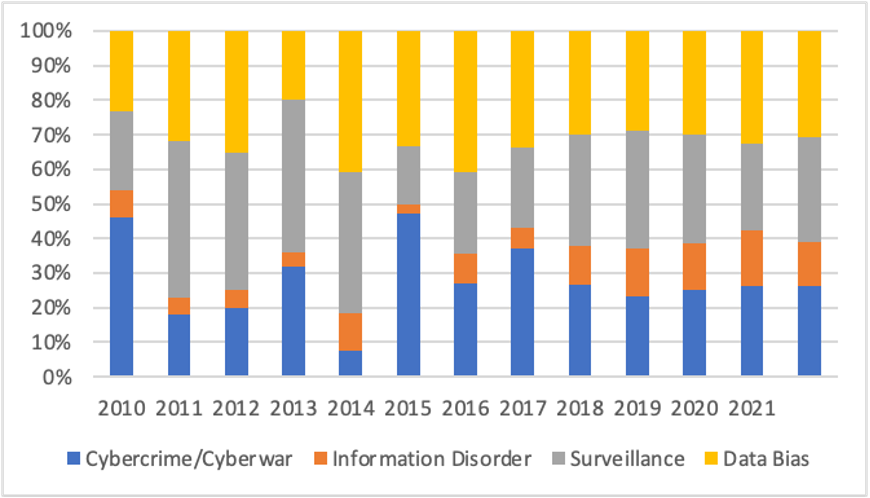

There are a few noticeable differences: In the early 2010s, some risk categories, such as information disorder and data bias, were not present at all for big data-centric articles. Looking at distinctiveness of risk categories per tech term (table 5), articles about AI seem more likely to refer to data bias than articles focused on big data (20.4% vs 15.7%, N=5423, χ2= 29.33, df= 1, p= .01). Conversely, big data-articles more often include references to surveillance and privacy invasion (20.0% vs 29.6%, N=5,423, χ2= 35.50, df= 1, p= .01).
|
Cybersecurity |
Information disorder |
Surveillance |
Databias |
N |
|
|---|---|---|---|---|---|
|
AI |
662 (17.3%) |
315 (8.3%) |
764 (20.0%) |
777 (20.4%) |
3817 |
|
Big Data |
263 (16.8%) |
77 (4.9%) |
475 (30.4%) |
252 (16.1%) |
1561 |
This difference is not entirely surprising. In the early big data discourse, questions of how expanding data collection invades people’s privacy was a common concern that led to attempts of stricter regulation of datafication processes in e.g., the European context. AI solutions often serve for forms of automated decision-making about individuals and can reproduce or create new inequalities and biases. This risk became more apparent with the actual deployment of AI solutions in different domains. These observations imply how the ongoing development of technologies and adoption in new contexts lead to the “discovery” of new risks.
Close-reading of data risk news
Privacy invasion and surveillance
Privacy invasion and surveillance describe the unsolicited collection of user data for different economic and/or political purposes that often remain hidden from users. Concrete examples are hidden data trackers in apps, cookies, data scraping from social media profiles without consent, or data leaks. Privacy invasion/surveillance is one of the most visible data risks in Western public discourses, which have turned more critical towards prevailing data practices. This is reflected in tech news reporting where forms of privacy invasion/surveillance are widely referred to. The extent to which unethical data collection practices are explained differs considerably between news articles. For example, coverage of specific controversies involving big tech companies attempts to explain what privacy invasion via e.g., data tracking means for lay people (e.g., Everything You Need to Know About Facebook and Cambridge Analytica [Wired, 2018]). Opinion pieces are particularly outspoken about how current data practices bear risks for individual privacy (Throw Your Laptop Into the Sea, the Surveillance Economy Will Still Win [NYT, 2019]; How Big Tech Plans to Profit from the Pandemic [NYT, 2021]). Articles that specifically focus on privacy issues discuss broader implications of datafication trends (e.g., Rethinking Privacy in an Era of Big Data [NYT, 2012]; How much is your personal data worth? [Guardian, 2014]); report about attempts on tech regulation (e.g., Why Silicon Valley Should Fear Europe's Competition Chief [WR, 2018]; British Panel Calls for Stricter Antitrust Rules on Tech Giants [NYT, 2019]); or explain how products and services may come with risks for individual privacy (e.g., RunKeeper talks smart watches, iPhone 5s and privacy issues for fitness apps [Guardian, 2013]; A Sneaky Path Into Target Customers’ Wallets [NYT, 2014]).
However, many articles merely mention privacy issues passingly without further discussing how they affect individuals. The exact negative consequences for users remain vague even in articles that explicitly focus on scandals involving privacy invasion, except for governmentally induced data surveillance for security and control purposes. Concerning “non-minority users”, it seems difficult to illustrate the exact harms of privacy invasion and surveillance, as the consequences of unethical data practices are highly contingent, partially unforeseeable, and potentially invisible for specific individuals. The most concrete negative consequences mentioned for general users in news articles are usually threats of manipulation in social media and targeted online advertising.
Data bias and algorithmic discrimination
With the rise of automated decision-making systems that rank and categorise people, various incidents involving biases and discrimination made news headlines in recent years. As with privacy, articles differ vastly regarding the depth to which these issues are discussed. Data bias connects to forms of racism, sexism, ageism, ableism, and their various intersections. The exact forms and effects are again context-dependent, but news articles tend to address four general categories: first, data bias that leads to exclusion from using tech efficiently (e.g., The Best Algorithms Still Struggle to Recognize Black Faces [Wired, 2019]). Respective articles explain how certain demographic groups cannot benefit from technology to the same extent as others. The second category concerns biases that lead to social and economic disadvantages in classification systems. Examples are automated recruitment solutions that reflect historical biases against women and minorities (e.g., The Commonality of A.I. and Diversity [NYT, 2018]). Affected groups are put at a disadvantage that is often deeply embedded in the data used to develop such systems (e.g., Rise of the racist robots – how AI is learning all our worst impulses [Guardian, 2017]). However, some articles explain how AI may have the reverse effect and can overcome human biases in the same domains (e.g., Start-Ups Use Technology to Redesign the Hiring Process [NYT, 2017]). The third category consists of data-driven systems for policing and controlling populations, in which specific demographic groups are overrepresented to their disadvantage (e.g., As Cameras Track Detroit’s Residents, a Debate Ensues Over Racial Bias [NYT, 2019]; ICE Used Facial Recognition to Mine State Driver’s Licence Databases [NYT, 2019]). The problem is not exclusion from technology, but how data and AI contribute to marginalisation and stigmatisation. A fourth category pertains to mis-categorisations of individuals in AI systems (e.g., ‘Nerd,’ ‘Nonsmoker,’ ‘Wrongdoer’: How Might A.I. Label You? [NYT, 2019]).
News reporting tends to locate causes in tech creators’ unawareness/ignorance over how their systems affect diverse social groups or governmental policies that have discriminatory effects. Causes are presented as cultural biases somewhat specific to the tech sector and/or general patterns of marginalisation and discrimination that have historical roots in society. Articles link data bias to questions of accountability (e.g., Sure, A.I. Is Powerful—But Can We Make It Accountable? [Wired, 2016]) and regulation (e.g., We Need a Law to Save Us From Dystopia [NYT, 2019]). It is also portrayed as a general challenge of AI (What Are the Biggest Challenges Technology Must Overcome in the Next 10 Years? [Gizmodo, 2019]). Some news items balance the downsides of data bias as a risk with the benefits of data-driven solutions for practical problems (e.g., Can A.I.-Driven Voice Analysis Help Identify Mental Disorders? [NYT, 2022]).
Overall, the different data bias framings focus on two dimensions of risk effect: 1) concrete instances in which tech excludes, marginalises, or targets specific demographic groups to their disadvantage, and 2) data bias as a general risk in society of vague impact that potentially becomes more relevant with increasing use of data and AI.
Cybersecurity
Digital infrastructures have various vulnerabilities that are exploited by malicious actors. This concerns individuals and organisations alike. Hacking, data theft, the spread of computer viruses and other forms of cyber-attacks and cybersecurity breaches are frequent topics in technology news. While diverse in shape, scope, and impact, these different threats share that they are directly intended digital incursions to either illegally retrieve immaterial goods (e.g., data, information, financial assets) or cause disruptions/damages to digital- and connected material infrastructures. These can be roughly placed in one of two overlapping categories: cyberwar and cybercrime. Both are often global in scope but the main differences between them are the intentions of the actors behind cyberattacks. State actors, such as military branches or intelligence services, usually aim for hampering technological progress, stealing intel, and harming other countries’ digital facilities. Respective news articles often focus on malicious activities involving China, Russia, Iran, or North Korea (e.g., U.S. Fears Data Stolen by Chinese Hacker Could Identify Spies [NYT, 2015]; The Next Front in Cyberwarfare [NYT, 2017]; Kremlin Warns of Cyberwar After Report of U.S. Hacking Into Russian Power Grid [NYT 2019]). In the case of China, cyberwarfare is frequently portrayed as a sub-dimension of larger geopolitical tensions with the US and the “West” in general (e.g., Xi’s Gambit: China Plans for a World Without American Technology [NYT 2021]).
Closely related is cybercrime, which takes form of data theft, cyber-vandalism, extortion, and criminal activities that aim for the extraction of monetary value via force or deception (e.g., Twitter Vigilantes Are Hunting Down Crypto Scammers [Wired, 2021]). In the framing of “cybersecurity”, issues related to cybercrime can often overlap with critical discussions of privacy invasion by companies through unsolicited data tracking (e.g., A Location-Sharing Disaster Shows How Exposed You Really Are [Wired, 2018]). In this context, news portrays data collection for marketing/advertising purposes as “almost criminal” activities that undermine user autonomy. Other related news articles aim to provide advice on how users can better protect their data with different tools or software/device settings (e.g., The Lightning YubiKey Is Here to Kill Passwords on Your iPhone [Wired, 2018]; Get a Password Manager. Here's Where to Start [WR, 2018]).
More remotely, cybercrime news can focus on illegal trade through anonymised digital networks such as the dark web to cybercrimes (Feds Smashed the Dark-Web Drug Trade. It’s already Rebounding [Wired, 2019]), although such criminal acts do not necessarily involve data extraction or deletion.
Information disorder
A more recent risk frequently addressed in tech news reporting concerns how social media platforms affect the structure and dynamics of public discourses: information disorder, which is an umbrella term for misinformation, disinformation, and mal-information (Ireton & Posetti, 2018). Questions of digital propaganda, spinning, and especially “fake news” emerged as subjects of intense public debate. Several articles frame information disorder as an existential threat to democracy (e.g., The Week in Tech: Democracy Under Siege [NYT, 2018]). A watershed moment for this debate were the US presidential elections in 2016, in which the expression ‘fake news’ went globally viral (Fuchs, 2018). The main concern about information disorder is a fragmentation of public discourses and subsequent dissolution of societal cohesion. However, news media also report about attempts for finding “remedies” (e.g., One Data Scientist’s Quest to Quash Misinformation [Wired, 2020]; YouTube’s Plot to Silence Conspiracy Theories [Wired, 2020]) and the need for regulation (e.g., How to Regulate Artificial Intelligence [NYT, 2017]). Interestingly, some articles argue that human agency offers a countermeasure to ill-intended algorithmic content distribution: ‘Computers are good at spreading lies. People can help stop them and mitigate the damage they cause' (NYT, 2020).
The different manifestations of information disorder are forms of manipulation that exploit the communicative logic of social networking media and algorithmic systems for information distribution. While these threats to public discourse culture need to be taken seriously, it is important to consider news organisations’ stakes and motivations in the critical discussion of information disorder. Often, little information is provided about how much of an actual impact “fake news” has on e.g., voter behaviour or how real so-called ‘filter bubbles’ are (Bruns, 2019). Especially mainstream news media are trapped in a tense relationship of dependency with social media platforms, which may contribute to sensationalism in reporting about the issue.
Discussion
The guiding research question of the present study is: How do news media frame data risks in their coverage of big data and AI? The main objective is to probe how tech news reporting can contribute to the formation of critical data literacy among media audiences.
Concerning awareness and visibility of data risks, the findings imply that Anglophone-Western media discourses have become more attentive -possibly sensitive- for ethical challenges and harmful effects of tech. Observations from the distance-reading show that increased media attention to data risks went hand in hand with the expansion of big data and AI adoption across societal domains. The more domains tech trends enter, the higher the probability that the news register harmful uses and effects. As data-driven technologies become more complex, so do the risks that are entailed in their widespread use. Tech reporting does have real potential for indicating to audiences what risks exist and in what contexts they matter for whom.
There are two dimensions in which tech news articles discuss data risks that need critical reflection: 1) what data risk(s) they cover, and 2) the way and extent to which they cover data risk(s). Regarding the first point, news articles differ considerably in how they frame different data risks’ scopes of impact. Privacy invasion and data surveillance appears most “established” as a focal point of discussions about data ethics, data politics, and data regulation with perceived relevance for a broad spectrum of social groups. Data bias is a problem mostly linked to the discrimination of minorities; this has fundamental implications for societal cohesion and should concern “everyone” but is still framed as an issue of primary concern for only certain demographic groups. The framing of Cyberwar/cybercrime has strong political connotations but can include concrete advice for individual users. Information Disorder is presented as a threat to a healthy democracy in which tech platforms are often portrayed as responsible. The comparative view reveals that each data risk category has become an item on the public agenda, and they are presented as of generally equal gravity in respect to ethical challenges. However, the data risk categories are not mutually exclusive but describe different emphases of perceived threats and/or undesirable effects associated with datafication and automation. AI that categorises people based on e.g., behavioural, and demographic data may pose risks of data bias and data surveillance simultaneously. Cybercrime can take the shape of privacy intrusion, e.g., when personal data are being stolen. It is important to chart the whole spectrum of possible negative effects caused by the misuse of data-driven technology and to assess how different data risks enable and potentially boost one another. The findings from the close-readings imply that the complex mutual affectivity and interrelationship between technologies, agency, and social impact are often implied but not always explicitly addressed in tech news.
Importantly, the list of data risks is not exhaustive and other types discussed in the literature were not detected during the analysis. Critical issues such as the digital divide (van Dijk, 2020), cyber-violence/cyberbullying (Giumetti and Kowalski, 2022), or social media addiction (Watson, 2022) did not emerge as categories. Admittedly, this could be a sampling effect and more research is needed to assess the extent of data risk representation in news reporting as an indicator for public awareness. However, it is not unlikely that certain risks are less newsworthy than others for diverse reasons connected to the attention economy of modern news media.
Regarding the extent of data risk reporting (point 2), the distant- and close-readings show how the news discourse seems to have become gradually more critical over time. An example is AI news in NYT, which in the early 2010s focused on technological capabilities (e.g., Computers Learn to Listen, and Some Talk Back [NYT, 2010]) but in recent years shifted to concerns about risks of automation (e.g., Not the Bots We Were Looking For [NYT, 2017]; All This Dystopia, and for What? [NYT, 2020]). This is not to say that tech news is today generally more negative than positive. Instead, tech news reporting appears nuanced about the value-risk balance of big data and AI, often presenting both benefits and downsides of specific innovations. While this is overall a positive characteristic, there are still news items that seem to reflect tech hype and hysteria (e.g., The AI Cold War That Threatens Us All [Wired, 2018]).
Tech news discussing data risks further differ regarding temporality and dimensionality, i.e., some focus on the present and concrete context-of-use while others envision the future and broad societal implications (e.g., 'Will Artificial Intelligence Enhance or Hack Humanity?', [Wired, 2019]). This can influence how risks are presented as “tangible”. Related to this is the varying extent to which data risks are addressed. Some articles offer in-depth stories that consider various contextual factors, while others merely drop relevant keywords that establish a connection between tech and certain data risks but without further elaborating why and how that matters for the social groups possibly affected. Data risks may have become more visible in public discourses in terms of how often they are raised but that does not necessarily mean that the respective issues and underlying causes are sufficiently elucidated for non-expert audiences. Lay audiences would need to have access to additional sources of information about diverse data risks e.g., via education and organisational communication.
The most tangible value for supporting critical data literacy among audiences have articles that explain for concrete contexts how datafication and automation have specific effects and how users can take action. Two types of tech news are exemplary for this: on the one hand, there are articles that outline how tech trends are political issues, how data practices need to be more ethical, and how regulation can mitigate risks (e.g., Data will change the world, and we must get its governance right [Guardian, 2017]; Privacy Isn’t a Right You Can Click Away [Wired, 2018]). Such news content provides necessary factual knowledge to understand the implications of datafication and automation for society conceptually, which can play a part in political opinion formation. On the other, there are articles that inform users about how they can protect themselves against different manifestations of data risks, especially regarding personal privacy and data security. This provides useful practical knowledge relevant for critical data literate individuals. However, such critical-empowering reporting can only be effective if it is part of continuous news coverage that closely monitors policy changes in tech services/products and informs audiences accordingly. To achieve such an educative mission, journalists themselves need to be critically data literate. Research implies that individual tech journalists are well-equipped for such a task (Nguyen & Hekman, 2020b). However, it needs to be further researched what the situation looks like for the journalistic profession in general.
To sum up, the analysis of tech news shows that risks are context-dependent discursive constructs that encapsulate distinguishable outcomes of at least partially uncertain developments. Risk discussions concern a lack of control over such potential consequences. Data risks are inherently social as in “man-made”; they are effects of the complex socio-technological assemblages that emerged over the past forty years. Large scale data collection is an opportunity for both private and public organisations, while it can pose a threat to individual freedom of citizens/users. Whether a potential outcome is considered a risk or not can vary greatly between stakeholders’ perspectives and situatedness. For citizens to form an opinion and be able to attain agency in data risk debates, it is essential that they are aware of potential threats, harms, and ethical challenges. This directly links critical data literacy to questions of data justice (Taylor, 2017), which aims to increase citizens’ sensitivity for data risks and to build-up resilience against data malpractices. News media can play an important role here by addressing societal implications through concrete examples for data risks without hype or hysteria. Gradually, they could contribute to the politicisation of big data and AI by shaping them into subjects of public concern and, eventually, parliamentary politics. However, their actual reach and influence has clear limitations. Not everyone affected by datafication and automation is interested in critical news about them. And not everyone who reads such news will adopt a more critical stance towards tech trends.
In addition to critical news reporting as a stimulator of public discursivity, additional measures can be taken by data-driven organisations themselves and public organisations that aim for citizen empowerment. Any organisation dealing with data should assess what data risks apply to their operations and devise clear and unambiguous communication strategies about their risk policies for their target groups. Important questions that should have clear answers include: what data risks apply to the services/products provided? Who is most likely to be affected? What measures are in place to mitigate them? How can we explain different data risks in ways accessible to different target groups? Regulators may then want to consider how data-driven organisations could be held accountable for providing this. Transparency about what data risks may apply and how they are mitigated can contribute to an increase of trust in data practices and build critical data literacy by instilling an understanding for how datafication and automation are used.
Conclusion
This study explored data risks as discursive constructs in public discourses by critically analysing news reporting about big data and AI. The findings show that data risks are diverse and affect different stakeholders to varying degrees, yet four risk categories seem to largely shape critical public debates on ethical challenges in the digital transformation: privacy invasion/surveillance, data bias/algorithmic discrimination, cybersecurity, and information disorder. News reporting on these issues connects to critical data literacy, i.e., a basic conceptual understanding of how these technologies have social effects on individual and societal levels. The paper adds to the theorisation of the societal implications of datafication and automation, especially with respect to how contemporary digital societies perceive and assess downsides and uncertainties of technology. Since data risks are inextricably tied to highly dynamic technological developments and their context-dependent adoptions as well as impacts, inventorying and assessing them should be approached as a quasi-permanent process.
There are several limitations to the present study. The sample is limited to Anglophone outlets and not fully representative for critical data discourses worldwide. Differences between discourse cultures need to be considered and comparative studies might be a viable route for future research. Next, the dictionary-approach that connected the manual and automated content analyses may have missed data risk occurrences that simply were not detected in the preceding inductive-qualitative part. More advanced forms of automated content analysis utilising supervised machine learning may increase the validity of the methodological approach. A follow-up study should include more diverse text sources to chart public discourses beyond news media (e.g., social media, public relations material, policy papers). To identify and develop strategies for dealing with risks, it needs both an empirical approach to understanding their underlying causes and critical reflections from a normative-ethical viewpoint. Future research should thus consider studies on lay audiences’ views and attitudes and explore regulatory interventions for data risk communication.
Nevertheless, the systematic categorisation provides a basis for further empirical investigation of how data risks are discursively constructed and represented in public discourses. It is also a starting point for developing framing approaches that make data risks understandable for diverse audiences and can contribute to building data literacy among the public. Furthermore, the overview of data risks can inform organisations’ communication strategies that make clear how they are premediating and addressing these challenges to protect users’ interests. Data risks are communication challenges for organisations that intend to build trust with their target groups. Each data risk needs a different strategy for minimising harm.
Data risks are not inevitable but entirely man-made. This may seem as a truism in academic and expert discourses, but one should simply not expect that lay audiences share the same fundamental assumptions about data-driven technology, especially when data and AI are often presented as value-free, objective, non-political, and unbiased.
References
Bareis, J., & Katzenbach, C. (2022). Talking AI into being: The narratives and imaginaries of national AI strategies and their performative politics. Science, Technology, & Human Values, 47(5), 855–881. https://doi.org/10.1177/01622439211030007
Beck, U. (2008). Weltrisikogesellschaft [Global Risk Society]. Suhrkamp Verlag.
Benjamin, R. (2019). Race after technology: Abolitionist tools for the new Jim Code. Polity.
Bollmer, G. (2018). Theorizing digital cultures. Sage. https://doi.org/10.4135/9781529714760
Bro, P., & Wallberg, F. (2014). Digital gatekeeping: News media versus social media. Digital Journalism, 2(3), 446–454. https://doi.org/10.1080/21670811.2014.895507
Browning, M., & Arrigo, B. (2021). Stop and risk: Policing, data, and the digital age of discrimination. American Journal of Criminal Justice, 46(2), 298–316. https://doi.org/10.1007/s12103-020-09557-x
Bruns, A. (2019). Filter bubble. Internet Policy Review, 8(4). https://doi.org/10.14763/2019.4.1426
Bunz, M., & Braghieri, M. (2021). The AI doctor will see you now: Assessing the framing of AI in news coverage. AI & SOCIETY, 37(1), 9–22. https://doi.org/10.1007/s00146-021-01145-9
Burscher, B., Vliegenhart, R., & Vreese, C. (2016). Frames beyond words. Applying cluster and sentiment analysis to news coverage of the nuclear power issue. Social Science Computer Review, 34(5), 530–545. https://doi.org/10.1177/0894439315596385
Cacciatore, M. A., Anderson, A. A., Choi, D.-H., Brossard, D., Scheufele, D. A., Liang, X., Ladwig, P. J., Xenos, M., & Dudo, A. (2012). Coverage of emerging technologies: A comparison between print and online media. New Media & Society, 14(6), 1039–1059. https://doi.org/10.1177/1461444812439061
Chen, B. X. (2022, November 2). Personal tech has changed. So must our coverage of it. The New York Times. https://www.nytimes.com/2022/11/02/insider/personal-tech-brian-chen.html
Couldry, N., & Mejias, U. A. (2019). The costs of connection: How data is colonizing human life and appropriating it for capitalism. Stanford University Press. http://www.sup.org/books/title/?id=28816
Dencik, L., & Sanchez-Monedero, J. (2022). Data justice. Internet Policy Review, 11(1). https://doi.org/10.14763/2022.1.1615
D’Ignazio, C., & Klein, L. F. (2020). Data feminism. The MIT Press. https://mitpress.mit.edu/9780262358538/data-feminism/
Donk, A., Metag, J., Kohring, M., & Marcinkowski, F. (2012). Framing emerging technologies: Risk perceptions of nanotechnology in the German press. Science Communication, 34(1), 5–29. https://doi.org/10.1177/1075547011417892
Entman, R. M. (1993). Framing: Toward clarification of a fractured paradigm. Journal of Communication, 43(4), 51–58. https://doi.org/10.1111/j.1460-2466.1993.tb01304.x
Flensburg, S., & Lomborg, S. (2021). Datafication research: Mapping the field for a future agenda. New Media & Society. https://doi.org/10.1177/14614448211046616
Fuchs, C. (2018). Digital demagogue: Authoritarian capitalism in the age of Trump and Twitter. Pluto Press. https://doi.org/10.2307/j.ctt21215dw
Giumetti, G. W., & Kowalski, R. M. (2022). Cyberbullying via social media and well-being. Current Opinion in Psychology, 45, Article 101314. https://doi.org/10.1016/j.copsyc.2022.101314
Goenaga, A. (2022). Who cares about the public sphere? European Journal of Political Research, 61(1), 230–254. https://doi.org/10.1111/1475-6765.12451
Gray, J., Gerlitz, C., & Bounegru, L. (2018). Data infrastructure literacy. Big Data & Society, 5(2), 1–13. https://doi.org/10.1177/2053951718786316
Grusin, R. (2010). Premediation: Affect and mediality after 9/11. Palgrave. https://doi.org/10.1057/9780230275270
Harcup, T., & O’Neill, D. (2016). What is news? News values revisited (again). Journalism Studies, 18(12), 1470–1488. https://doi.org/10.1080/1461670X.2016.1150193
Hartman, T., Kennedy, H., R, S., & Jones, R. (2020). Public perceptions of good data management: Findings from a UK- based survey. Big Data and Society, 7(1), 1–16. https://doi.org/10.1177/2053951720935616
Hinds, J., Williams, E. J., & Joinson, A. N. (2020). “It wouldn’t happen to me”: Privacy concerns and perspectives following the Cambridge Analytica scandal. International Journal of Human-Computer Studies, 143, Article 102498. https://doi.org/10.1016/j.ijhcs.2020.102498
Ireton, C., & Posetti, J. (Eds.). (2018). Journalism, ‘fake news’ & disinformation. Handbook for journalism education and training. United Nations Educational, Scientific and Cultural Organization. https://unesdoc.unesco.org/ark:/48223/pf0000265552
Kitchin, R. (2021). The data revolution. A critical analysis of big data, open data & data infrastructures (2nd ed.). SAGE.
Landau, S. (2017). Listening in: Cybersecurity in an insecure age. Yale University Press.
Langer, A. I., & Gruber, J. B. (2020). Political agenda setting in the hybrid media system: Why legacy media still matter a great deal. The International Journal of Press/Politics, 26(2), 313–340. https://doi.org/10.1177/1940161220925023
Laor, T., Rosenberg, H., & Steinfeld, N. (2021). Oh, no, Pokémon GO! Media panic and fear of mobility in news coverage of an augmented reality phenomenon. Mobile Media & Communication, 10(3), 365–386. https://doi.org/10.1177/20501579211052227
Lopez, P. (2021). Bias does not equal bias: A socio-technical typology of bias in data-based algorithmic systems. Internet Policy Review, 10(4). https://doi.org/10.14763/2021.4.1598
Luhmann, N. (1991). Soziologie des Risikos [Risk: A Sociological Theory]. De Gruyter.
Lupton, D. (2013). Risk (2nd ed.). Routledge.
Marks, L. A., Kalaitzandonakes, N., Wilkins, L., & Zakharova, L. (2007). Mass media framing of biotechnology news. Public Understanding of Science, 16(2), 183–203. https://doi.org/10.1177/0963662506065054
Mejias, U. A., & Couldry, N. (2019). Datafication. Internet Policy Review, 8(4). https://doi.org/10.14763/2019.4.1428
Nguyen, D. (2017). Europe, the crisis, and the internet. A web sphere analysis. Palgrave MacMillan. https://doi.org/10.1007/978-3-319-60843-3
Nguyen, D. (2021). Mediatisation and datafication in the global COVID-19 pandemic: On the urgency of data literacy. Media International Australia, 178(1), 210–214. https://doi.org/10.1177/1329878X20947563
Nguyen, D., & Hekman, E. (2022a). A ‘new arms race’? Framing China and the U.S.A. in A.I. news reporting: A comparative analysis of the Washington Post and South China Morning Post. Global Media and China, 7(1), 58–77. https://doi.org/10.1177/20594364221078626
Nguyen, D., & Hekman, E. (2022b). The news framing of artificial intelligence: A critical exploration of how media discourses make sense of automation. AI & SOCIETY. https://doi.org/10.1007/s00146-022-01511-1
Nguyen, D., & Nguyen, S. (2022). Data literacy as an emerging challenge in the migration/refugee context: A critical exploration of communication efforts around “refugee apps”. International Journal of Communication, 16, 5553–5557.
Paek, H.-J., & Hove, T. (2017). Risk perceptions and risk characteristics. In Oxford Research Encyclopedias, Communication (pp. 1–14). Oxford University Press. https://doi.org/10.1093/acrefore/9780190228613.013.283
Paganoni, M. C. (2019). Framing big data. A linguistic and discursive approach. Palgrave Pivot. https://doi.org/10.1007/978-3-030-16788-2
Pasquale, F. (2015). The black box society: The secret algorithms that control money and information. Harvard University Press. https://doi.org/10.4159/harvard.9780674736061
Peters, B. (2007). Der Sinn von Öffentlichkeit [The meaning of the public]. Suhrkamp Verlag.
Peterson, E. (2020). Paper cuts: How reporting resources affect political news coverage. American Journal of Political Science, 65(2), 443–459. https://doi.org/10.1111/ajps.12560
Řehůřek, R., & Sojka, P. (2010). Software framework for topic modelling with large corpora. Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, 46–50. https://doi.org/10.13140/2.1.2393.1847
Roskos-Ewoldsen, B., Davies, J., & Roskos-Ewoldsen, D. R. (2004). Implications of the mental models approach for cultivation theory. Communications. The European Journal of Communication Research, 29(3), 345–363. https://doi.org/10.1515/comm.2004.022
Scheufele, D. A., & Lewenstein, B. V. (2005). The public and nanotechnology: How citizens make sense of emerging technologies. Journal of Nanoparticle Research, 7(6), 659–667. https://doi.org/10.1007/s11051-005-7526-2
Simon, J., Wong, P.-H., & Rieder, G. (2020). Algorithmic bias and the Value Sensitive Design approach. Internet Policy Review, 9(4). https://doi.org/10.14763/2020.4.1534
Solove, D. J. (2021). The myth of the privacy paradox. The George Washington Law Review, 89(1), 1–42. https://doi.org/10.2139/ssrn.3536265
Srnicek, N. (2017). Platform Capitalism. Polity.
Taylor, L. (2017). What is data justice? The case for connecting digital rights and freedoms globally. Big Data & Society, 4(2), 1–14. https://doi.org/10.1177/2053951717736335
Van Dijck, J., de Winkel, T., & Schäfer, M. T. (2021). Deplatformization and the governance of the platform ecosystem. New Media & Society, 1–17. https://doi.org/10.1177/14614448211045662
Van Dijk, Jan, J. (2020). The Digital Divide. Polity.
Van Duyn, E., & Collier, J. (2018). Priming and fake news: The effects of elite discourse on evaluations of news media. Mass Communication and Society, 22(1), 29–48. https://doi.org/10.1080/15205436.2018.1511807
Vicente, P. N., & Dias-Trindade, S. (2021). Reframing sociotechnical imaginaries: The case of the Fourth Industrial Revolution. Public Understanding of Science, 30(6), 708–723. https://doi.org/10.1177/09636625211013513
Von Pape, T., Trepte, S., & Mothes, C. (2017). Privacy by disaster? Press coverage of privacy and digital technology. European Journal of Communication, 32(3), 189–207. https://doi.org/10.1177/0267323117689994
Watson, J. C., Prosek, E. A., & Giordano, A. L. (2022). Distress Among Adolescents: An Exploration of Mattering, Social Media Addiction, and School Connectedness. Journal of Psychoeducational Assessment, 40(1), 95–107. https://doi.org/10.1177/07342829211050536
Wolff, J. (2021). "Cyberwar by almost any definition”: NotPetya, the evolution of insurance war exclusions, and their application to cyberattacks. Connecticut Insurance Law Journal, 28, 85–129.
Wynne, B. (2002). Risk and environment as legitimatory discourses of technology: Reflexivity inside out? Current Sociology, 50(3), 459–477. https://doi.org/10.1177/0011392102050003010
Zarouali, B., Helberger, N., & Vreese, C. (2021). Investigating algorithmic misconceptions in a media context: Source of a new digital divide? Media and Communication, 9(4), 134–144. https://doi.org/10.17645/mac.v9i4.4090
Zuboff, S. (2019). The age of surveillance capitalism: The fight for a human future at the new frontier of power. Profile Books.
Add new comment